|
|||||
Accueil > Activités > Projets R&D >Datascale
Big Data et Calcul Haute performance
Porteur : :
Decembre 2014 :
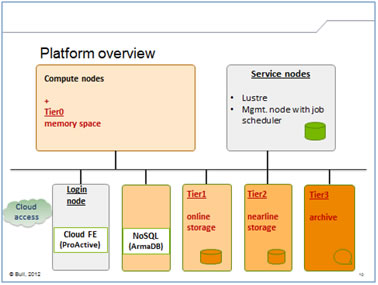
L’objectif principal est de développer les synergies entre les domaines du Big Data et du calcul haute performance (ou HPC - High Performance Computing), et plus concrètement de développer des briques technologiques Big Data qui viendront enrichir l’écosystème HPC.
Ces briques technologiques couvrent trois thèmes amenés par la convergence HPC – Big Data :
Le projet s’attache également à évaluer l’intérêt de ces briques technologiques en réalisant des démonstrateurs basés sur des cas réels d’application, avec passage à l’échelle, dans les domaines
Les objectifs projets, articulés autour de la convergence HPC et Big Data, se trouvent parfaitement en phase avec les évolutions actuellement observées dans le marché HPC, (voir par exemple l’émergence de la problématique HPDA (High Performance Data Analytics, encore mise en lumière par IDC lors du salon Supercomputing 2014). Le projet DataScale aura été présenté lors de l’évènement Teratec 2014 (workshop Big Data), et présent au salon Big Data d’Avril 2014.
L’année 2014 aura vu la définition at la réalisation des trois briques technologiques prévues
Ainsi que l’installation intégrée de ces briquées sur une plateforme HPC dédiée (plateforme NovaX, hébergée chez Bull)
Les trois cas d’usages ont été définis, et des premiers jeux de données significatives ont pu être éprouvées : il est trop tôt pour disposer de résultats consolidés, mais les essais réalisés démontrent une bonne complémentarité entre les technologies choisies et les usages prévus . Plus précisément, on peut noter
Octobre 2013 - Le projet DataScale fédère un éventail de partenaires très divers – grands laboratoires de recherche, PME et grandes entreprises – dont l’ambition commune est de créer des solutions Big Data efficaces, adaptées à des cas réels d’utilisation dans le domaine du calcul haute performance. DataScale est un projet sur deux ans, lancé en juin 2013 dans le cadre des “Investissements d’Avenir” mis en place par le gouvernement français. Sa mission principale est de développer les synergies entre les domaines du Big Data et du calcul haute performance (ou HPC - High Performance Computing), et plus concrètement de développer des briques technologiques Big Data qui viendront enrichir l’écosystème HPC. Ces briques technologiques couvriront trois thèmes essentiels pour la problématique Big Data :
Le projet s’attachera en outre à évaluer l’intérêt de ces briques technologiques en réalisant des démonstrateurs basés sur des cas réels d’application, avec passage à l’échelle, dans les domaines de la détection d’événements sismiques, de la gestion de clusters HPC et de l’analyse de produits multimédia. Le projet regroupe des partenaires aux profils très divers, qui apportent chacun leurs compétences propres, leur savoir-faire dans des domaines aussi variés que les infrastructures, le HPC, les bases de données, le Cloud Computing, l'administration de système, le multimédia, la fouille de donnée et le domaine sismique. En s’appuyant sur leurs connaissances des besoins du marché, les partenaires DataScale proposeront des méthodes et algorithmes pertinents et développeront des solutions susceptibles de donner naissance à de futurs produits. La variété d'approches et de savoir-faire des partenaires garantit une large couverture des problèmes et des solutions du Big Data, ainsi que la constitution de synergies que le projet pourra exploiter. Denis Caromel (fondateur et CEO d’ActiveEon) déclare "Le Big Data est très souvent, trop souvent, associé avec une problématique MapReduce, et en particulier Hadoop – ce qui conduit les entreprises à faire des choix technologiques inadéquats. En réalité, la problématique de la gestion de grandes quantités de données est souvent diverse, et nécessite une combinaison de solutions, telles que orchestration et scheduling, déploiement, optimisation des ressources. DataScale va renforcer les offres existantes des partenaires français du projet, et conduire rapidement à une solution complète et souveraine. >>.
|
||||