 |
|||||

Accueil > Activités > Projets R&D > OPENGPU
|
Porteur :
Le projet OpenGPU a été conçu en 2009 autour des paris technologiques suivants :
En cette fin 2012, ces trois paris se révèlent avoir été pertinents et ont permis au projet OpenGPU de poursuivre durant toute sa durée sur des bases solides l’ensemble de ses travaux. Le GPU Computing est devenu incontournable pour la conception de tous les calculateurs actuels et futurs et l’intégration des GPUs au sein de tous les processeurs (Intel, AMD, ARM) va rendre la programmation hybride de plus en plus nécessaire. A ce titre, le projet OpenGPU aura permis à l’ensemble des partenaires, ainsi qu’à la communauté qui a été associée aux différents évènements, de se préparer au mieux pour maîtriser ces nouvelles donnes technologiques. Le standard OpenCL, malgré un démarrage complexe, est aujourd’hui la cible de très nombreux développements par des acteurs majeurs des nouvelles technologies comme Apple, Google et Intel. Les premières versions que le projet OpenGPU a eu l’occasion de tester ont d’abord poussé les développements vers l’environnement CUDA dont les performances et la richesse du SDK n’autorisaient aucun doute sur la pertinence de ce choix. Ce standard a cependant très rapidement évolué et a réussi à combler son retard sur tous les points évoqués précédemment. La prochaine standardisation du profil OpenCL par le groupe Kronos pour les processeurs ARM va ouvrir à cette plateforme l’immense marché de la mobilité et du « HPC portable ». Les compétences acquises pendant le projet OpenGPU devraient permettre une mise en œuvre simple et rapide des codes de calcul sur cette architecture et permettre d’envisager de nouveaux modèles de déploiement associant flexibilité et performances. Enfin, les gains obtenus par les partenaires démonstrateurs ont validé l’appropriation de l’approche GPU Computing par des secteurs aussi différents que la génomique ou la météorologie. Les formations initiales visant à une mise à niveau globales des compétences ont fluidifié la communication entre les partenaires et ouverts ceux-ci à la prise en compte de librairies métiers basées sur des composants hybrides. La modernisation des codes, afin que ceux-ci soient aptes à être exécutés sur de telles architectures, a été l’occasion de reprendre en main ces chaînes logicielles et de rationaliser leurs futurs développements. Le projet OpenGPU a été dans ce sens très bénéfique à un écosystème pour lequel la puissance de calcul est un atout vital pour son développement
Les GPUs (Graphics Processing Units) deviennent une solution de plus en plus prometteuse pour répondre au besoin croissant de puissance de calcul des traitements associés aux nouvelles méthodes industrielles de conception ou de simulation numérique. Aujourd’hui très propriétaire, essentiellement axé sur le graphisme/multimédia et exclusivement développés par des fabricants informatiques américains (NVidia, ATI, Intel, IBM), les GPU séduisent de nombreux laboratoires et industriels à la recherche de standards et de puissance de calcul plus massive pour un coût contrôlé et une efficacité énergétique améliorée. Ces travaux restent cependant isolés ou dispersés, bridés par l’absence de standards réels et d’outils suffisamment interopérables. Les acteurs européens sont de plus pratiquement absents de toute représentation dans les organismes de normalisation internationaux, ce qui exclut un dialogue constructif avec les fournisseurs de matériels GPU. Les enjeux sont donc aujourd’hui :
Le projet OpenGPU est né de ce constat et vise en particulier à réunir laboratoires spécialisés, industriels grandes entreprises et PME intéressés par ce sujet autour d’un projet collaboratif ambitieux permettant de faire face à ces enjeux. La localisation du projet au cœur du Groupe thématique OCDS du Pôle SYSTEMATIC Paris Région ainsi que les liens établis avec des démonstrateurs partenaires des Pôles Cap Digital et Medisen ouvrent à la fois des perspectives d’excellence technologique en HPC dans le monde industriel et le portage vers des applications orientées marchés dans la simulation, la prospection pétrolière et la biologie. En lien avec le Pôle TERATEC, le projet OpenGPU permettra de fédérer de nombreux acteurs de toute taille autour du plus gros projet français voire européen autour des GPUs localisé dans la Région Ile de France. Il servira de base à la recherche de partenariats internationaux et notamment les grands fabricants de plate-formes matérielles haute performance à base de GPU. L’ambition est à terme de construire autour du projet OpenGPU un pôle d’excellence économique et international basé géographiquement en Ile de France, capable d’attirer des acteurs industriels étrangers –fabricants, éditeurs, grandes entreprises, laboratoires et start-up- et constituer le 1er pôle Européen de recherche et développement dans le domaine des architectures hybrides.
Les GPUs (Graphics Processing Units) deviennent une solution de plus en plus prometteuse pour répondre au besoin croissant de puissance de calcul et de traitement des applications numériques, des nouvelles méthodes de conception ou des simulations numériques liées à la recherche. Depuis l'année 2005, la montée en fréquence des processeurs généralistes a laissé la place à la multiplication des cœurs (core) rendant ces solutions plus complexes à exploiter. Dans le même temps, les GPUs ont évolué vers des architectures moins spécialisées rendant leur usage pour des calculs ou des traitements de données envisageable. Cette évolution a été accompagnée par l'émergence d‘architectures unifiées des GPU et en 2008 par la finalisation du standard OpenCL offrant une perspective intéressante pour la programmation de ces architectures. La puissance et le ratio puissance/consommation des GPUs étant supérieurs à ceux des CPUs standards, l’utilisation des GPUs représente une opportunité permettant de disposer de plus de puissance à un coût moindre et pour consommation d'énergie maitrisable. Le projet OpenGPU se propose d’exploiter cette opportunité avec un triple objectif:
Le projet Open GPU comporte donc trois grands volets qui sont à la fois complémentaires et en synergie les uns avec les autres dans un but d'augmentation réciproque de la valeur dans chacun des domaines.
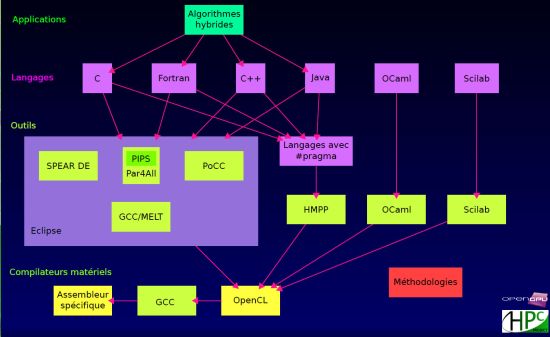
Convertir un code existant en code parallèle ou développer une application parallélisée est une tâche difficile pour des raisons multiples: manque de formation et d'expertise des développeurs, nouveauté et complexité des architectures multi-core (de deux à plusieurs centaines de cores), hétérogénéité du matériel, complexité intrinsèque de la parallélisation. Le projet OpenGPU a pour objectif de développer, synthétiser et intégrer dans l'environnement Eclipse l'ensemble des outils nécessaires à l'aide à la parallélisation d'applications écrites en langage C, C++, Java ou Fortran. Le standard OpenCL servira de format pivot afin d'assurer la portabilité des optimisations vers l'ensemble des architectures parallèles (CPU, GPU, OpenMP, MPI, Pthread, …). Le projet OpenGPU se réserve également la possibilité de cibler d'autres langages propriétaires (PTX ou autre langage spécifique à certaines architectures). Ces outils pourront être complétés par d'autres logiciels de mise au point (debugger) afin d'assurer la maîtrise maximale de la parallélisation en fonction des différents besoins. Cet ensemble d'outils intégrés sera proposé sous la forme d'un projet Open Source avec une licence respectueuse des ambitions de tous les partenaires du projet, sur un modèle permettant leur propagation rapide et mondiale.
La plupart des grandes librairies sur lesquelles s'appuient les industriels pour leurs calculs, simulations ou développements embarqués ne sont que peu (ou pas du tout) parallélisées actuellement. Cet état de fait empêche ces chaînes logicielles de bénéficier des gains de puissance de nouvelles architectures matérielles. Leur re-développement ou l'introduction de la parallélisation dans certaines parties critiques du code est un problème majeur pour ces applications qui n'ont pas été conçues pour être déployées sur des machines hautement parallèles. Le projet Open GPU concernera dans un premier temps l'étude des code des démonstrateurs avec les équipes d'experts en parallélisation, puis dans un deuxième temps, à l'aide des outils cités précédemment, la parallélisation de tout ou parties des librairies métiers des partenaires du projet. Cette dimension du projet apportera un double bénéfice: la validation sur des exemples grandeur nature des outils de parallélisation et l'optimisation des librairies industrielles pour les architectures parallèles (CPU, GPU, FPGA, Cell, …). Les trois domaines choisis en priorité dans le cadre du projet OpenGPU sont: la sécurité, la simulation et la biologie. La mise en forme de « bonnes pratiques » (design patterns) de parallélisation sous forme d'une bibliothèque OpenCL ou d'un corpus de règles de codage ouvrira le partage des acquis du projet OpenGPU aux membres du Club des utilisateurs du projet, puis à l'ensemble de la communauté HPC.
La mise en place des applications parallélisées nécessite de prendre en compte un grand nombre de paramètres: nombre et typologie des processeurs, systèmes d'exploitation, ordonnancement et répartition des tâches de calculs. Le projet OpenGPU serait incomplet si cette dimension de déploiement n'était pas prise en compte. L'intégration des outils comme OpenMP ou MPI le plus en amont possible dans la chaîne d'optimisation garantira une pleine exploitation des moyens de calculs sur lesquels seront déployées les applications parallélisées. Le projet Open GPU s'appuiera sur les compétences déjà acquises par les partenaires du projet dans le domaine des architectures HPC ou GPU et de la compilation pour coller au mieux avec les systèmes ciblés pour les déploiements. Ces trois volets s’appuieront sur une plateforme de benchmark et une approche visant à valider l’excellence énergétique des solutions.
La validation des optimisations apportées aux démonstrateurs devra être effectuée dans un cadre rigoureux afin de qualifier et de mesurer au mieux les gains obtenus à l'aide d'outils statistiques appropriés. Le projet OpenGPU mettra en œuvre une plate-forme matérielle et logicielle générique permettant à chaque démonstrateur de faire tourner ses tests, d'en créer de nouveaux si nécessaire et d'utiliser les outils de visualisation et d'analyse pour la validation des résultats. Le projet OpenGPU garantira l'étanchéité des codes sources, des données de benchmarks et des résultats associés. Ces résultats seront publiés suivant deux indicateurs clés que sont la performance et l'optimisation énergétique.
L'optimisation des chaînes de calculs par la parallélisation devrait également permettre une meilleure utilisation du taux d'occupation des serveurs et de bénéficier du rapport Gflops/watt très en faveur des nouveaux matériels à base de GPU. Le projet Open GPU vise en particulier à valider l'efficacité énergétique apportée par ces optimisations et à qualifier des configurations matérielles et logicielles dont le bilan énergétique et carbone est optimal, en rapport avec les normes actuelles ou à venir.
|
|